

install.packages("SmartEDA") #For Exploratory data analysis
library("SmartEDA")
#Read dataset
data=read.csv("Book1.csv",head=T, sep=";")
#Data preprocessing - Set binary variables as factors (including CustID since this will not be used in any analysis)
data$Custid=as.factor(data$Custid)
data$Kidhome=as.factor(data$Kidhome)
data$Teenhome=as.factor(data$Teenhome)
data$SMRack=as.factor(data$SMRack)
data$LGRack=as.factor(data$LGRack)
data$Humid=as.factor(data$Humid)
data$Spcork=as.factor(data$Spcork)
data$Bucket=as.factor(data$Bucket)
data$Access=as.factor(data$Access)
#First table information
ExpData(data=data,type=1,DV=NULL)

#Summary statistics for continuous variables
stat=ExpNumStat(data,by=c("GA"),gp="LGRack",Qnt=NULL,MesofShape=2,Outlier=FALSE,round=3)
#to exclude some information provided in the summary table of ExpNumStat() function that I don't want to visualize.
stat=stat[,-c(4,5,6,7,8,9,10,17)]


#Analysing customers with webvisits=0
stat_webpurch=ExpNumStat(subset(data,WebVisit==0),by=c("A"),Qnt=NULL,MesofShape=2,Outlier=FALSE,round=3)
stat_webpurch=stat_webpurch[,-c(4,5,6,7,8,9,10,17)]

#Excluding customers with Webvisit <=0
data=subset(data,WebVisit>0)
Let's now do some visualization:
####Visualization###
#Barplots for categorical variables
ExpCatViz(data,gp=NULL,fname=NULL,clim=10,margin=2,Page = c(3,3))


We can see that in what concerns LGRack, the majority of the customers didn't buy it (93%). The same trend with the other accessories is seen, since in every variable we can see that the higher percentage corresponds to "customer didn't buy". In webvisits, we can see that the majority of customers visted the website on average 7 times per month.
#Continuous variables taking into account target variable
ExpNumViz(data,gp="LGRack",type=1,nlim=NULL,fname=NULL,col=c("pink","yellow","orange"),Page=c(3,3))

From the output we can see that customers who bought the LGRack have higher income, higher monetary value, are elder, and also more frequent customers. We are also able to see that in some variables we have outliers, like on Income, Monetary,Frquency, LTV, Recency and Perdeal.
Now that we have made some exploratory analysis (this is not the core of the post so I didn't get deep on this topic), let's build our tree, after excluding from the analysis the other categorical variables and after changing the variables which are represented in percentages % to absolute value:
#Exlude categorical variables (except LGRack) from dataset
data=data[,-c(1,6,7,21,23,24,25,26)]
#Change variables
for(i in 9:16){
data[,i]=(data$Monetary*data[,i])/100
}
What confidence can we have in the performance of the model we are about to build?
One of the most practical ways of responding to this question is to test the model using new cases of customer decisions (bought or not bought), and to account for the incorrect decisions, when compared with the customer decisions made (predicted) by the decision tree.One way to simulate the existence of more cases to test our model is to divide the cases that we have into two sub-sets: one to obtain the model; and another to test it. Let's see how to do this in R:
# total number of rows in the data frame
n <- nrow(data)
# number of rows for the training set (80% of the dataset)
n_train <- round(0.80 * n)
# create a vector of indices which is an 80% random sample
set.seed(123) # set a random seed for reproducibility
train_indices <- sample(1:n, n_train)
# subset the data frame to training indices only
train <- data[train_indices, ]
# exclude the training indices to create the test set
test <- data[-train_indices, ]
Okay, so now we are ready to start building our decision tree:
#Installing packages
library(rpart)
#Creating the tree in the training dataset: method="class" specifies this is a classification tree
data_model <- rpart(formula = LGRack ~.,data = train,method = "class")
data_model
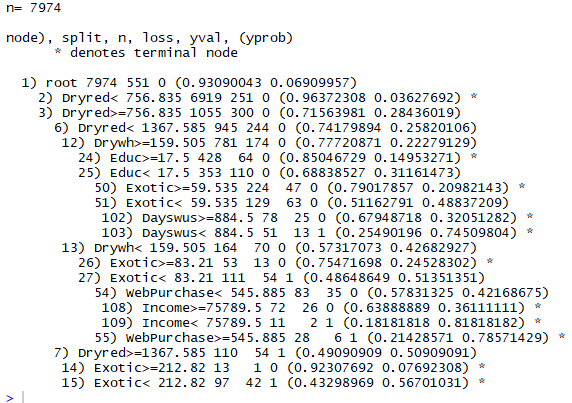
First, the R tells us the number of cases used to obtain the model. Next, a series of lines representing the different tests and nodes of the tree are presented. These are presented following a certain indentation and with an associated number, in order to better understand the hierarchy of the tests. Higher indentation means that the test / node is situated at a lower level in the tree. Thus, in this concrete example the first line identified with the number 1 gives us the information concerning the root node of the tree, before performing any test on a variable.
According to this information, we can see in the root node, that before we know / test the value of any variable, the best decision would be "0" (i.e. "not bought"). This decision is supported by the fact that of the 7974 examples given to R only 551 are of class "1=bought" which leads to a probability of 93% of any customer being a case of "not bought", and a 6.9% probability of being a case of "bought". These probabilities are the numbers presented in parentheses. From this root node we have two derivations depending on the value of the Dryred variable. These derivations are identified by numbers 2 and 3, and correspond to the next level of indentation.
Of the 7974 cases provided to R, 6919 customers have Dryred monetary value <756$ and in these, the majority class is "not bought", only 251 correspond to situations where customer bought the LGRack. If the customer has Dryred monetary value <756$ than a decision is reached (the R indicates this by placing a "* " on the line), which in this case is not bought (the probability of a customer to not buy the LGRack is 96%)
In summary, using the numbers and indentation, you can get an idea of the shape of the decision model obtained with the rpart function.
Let's now visualize the tree:
#Plotting tree
install.packages("rpart.plot")
library(rpart.plot)
boxcols <- c("pink", "palegreen3")[data_model$frame$yval]
par(xpd=TRUE)
prp(data_model, faclen=0, cex=.6, extra=5, box.col=boxcols)

Now we can obtain the tree predictions for the separate sample cases of testing:
#Predicting LGRack for test data
class_prediction <- predict(object = data_model, # model object
newdata = test, # test dataset
type = "class") # return classification labels
These predictions can now be compared to the true values of the test cases and thus get an idea of tree performance:
# calculate the confusion matrix for the test set
library(caret)
confusionMatrix(data = class_prediction, # predicted classes
reference = test$LGRack) # actual classes

conf <- table(test$LGRack,class_prediction)
error_rate <- 100 * (conf[1,2]+conf[2,1]) / sum(conf)
error_rate

#Accuracy:
acc=sum(test$LGRack==class_prediction)/length(class_prediction)




It was really a nice post and i was really impressed by reading this Data Science online Training Hyderabad
ReplyDeleteThank you Teju! Unfortunately I hadn’t much time to continue but soon I will start again with the posts! Thanks for sharing the link also 😊
DeleteI wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post. Admond Lee
ReplyDeleteThanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for. install tensorflow anaconda
ReplyDelete