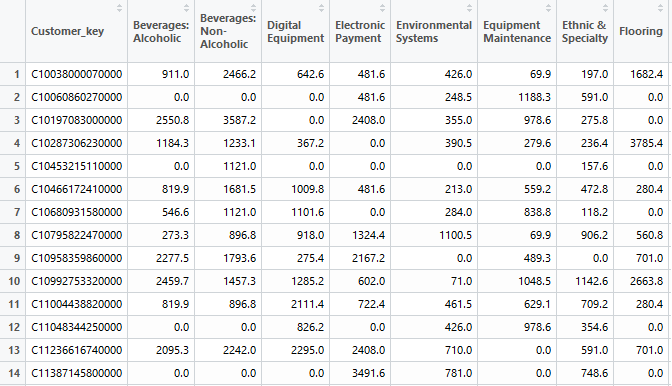
I will segment the customer database according to Sales amount spent and Number of categories bought by customer. Before going into further details, and before starting the analysis, let me share something with you:
This week i found in Linkedin a very interesting post on datascience+ website, which is "An online community for showcasing R & Python tutorials. It operates as a networking platform for data scientists to promote their talent and get hired. Our mission is to empower data scientists by bridging the gap between talent and opportunity."
I was just browsing on this site and I found this "Editorial Stylebook" that explains how authors can be consistent for writing interesting and relevant tutorials. Some of the questions they advise to address are pasted in the end of this post, with my answers!
Now, let's go into the analysis of today!
The segmentation I will perform has the main objective of identify tactical consumer groups. With this approach, we are able to understand how our customers behave with more detail and thus better target them.
The dataset:
Now, let's go into the analysis of today!
The segmentation I will perform has the main objective of identify tactical consumer groups. With this approach, we are able to understand how our customers behave with more detail and thus better target them.
The dataset:
InvoiceNo: Unique Invoice number. Nominal, if starting with "C" it means cancellation.
StockCode: Unique Product (item) code. Nominal
StockCode: Unique Product (item) code. Nominal
Description: Product (item) name. Nominal.
Quantity: The quantities of each product (item) per transaction.
InvoiceDate: Invoice Date and time.
Quantity: The quantities of each product (item) per transaction.
InvoiceDate: Invoice Date and time.
UnitPrice: Unit price.
CustomerID: Unique Customer number.
CustomerID: Unique Customer number.
Country: Country name.
#Installing packages
install.packages("reshape2")
install.packages("dplyr")
install.packages("ggplot2")
install.packages ("stargazer")
library("reshape2")
library("dplyr")
library("ggplot2")
library("stargazer")
To read the dataset, I used the "Import dataset" tool in RStudio.
#Selecting only customers from Country "United Kingdom"
Online_Retail_f=subset(Online_Retail,Country=="United Kingdom")
Dataset:

#Excluding cancelations
Online_Retail_f=subset(Online_Retail_f, Quantity>0)
#Creating variable "Sales" as Sales = quantity*price
Online_Retail_f$sales= Online_Retail_f$Quantity* Online_Retail_f$UnitPrice
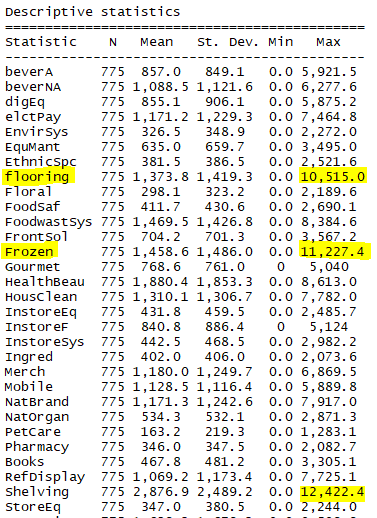
stargazer(Online_Retail_f,omit= c("InvoiceNo","StockCode","Description", "InvoiceDate"),type = "text", title="Descriptive statistics", digits=1)

#Removing cases where UnitPrice is negative
Retail=subset(Online_Retail_f,UnitPrice>0)
#Removing cases where CustomerID is null
Retail=subset(Retail,!is.na(CustomerID))
#Watching summary statistics again
stargazer(Retail,omit= c("InvoiceNo","StockCode","Description", "InvoiceDate"),type = "text", title="Descriptive statistics", digits=1)

I also notice that maximum values for Unit Price and Quantity are strange so let's check also what are the cases where this is happening. I will check case by case, by sorting the columns in the dataset viewer:

#Selecting only cases where UnitPrice is bigger then 3 cents
Retail=subset(Retail, UnitPrice>0.03)
Let's now reshape the transactional dataset into a dataset where I will have for each customer, the total number of different categories bought and the total amount spent. In my last post, I used a different approach on R to reshape the file but this time, I found this "sqldf" package which allows to deal with data with SQL queries , which is the best way for me to do it !
#Installing package and creating a new reshaped dataset
require(sqldf)
Segm_table=sqldf("
SELECT CustomerID, COUNT(distinct(StockCode)) as P, SUM(sales) as M
FROM Retail
GROUP BY CustomerID")
#Different command for summary statistics
summary(Segm_table)

We are able to see that maximum values for total categories and total sales are very high so probably they will be treated as oultiers. Let's check for outliers and exclude them as they can influence the choice of the intervals for the segmentation variables, as we will see further in this analysis.
Last post, I presented a function which I found to be very usefull to deal with outliers. Nevertheless, and since for beginners in R language, it can be of difficult interpretation the function, I will present here a new (and very simplified) approach to deal with it.#First, to check the outliers of Sales and Products amounts, we call the boxplot.stats function and retreive the outliers with $out command.
outliers = boxplot.stats(Segm_table$M)$out
outliers2= boxplot.stats(Segm_table$P)$out
#Then we create two columns which are the "outliers identifiers". OutliersM will have values 1 if the value of the variable "M" (sales) was found as an outlier and 0 if it was not. The same for OutliersP
Segm_table$OutliersM = ifelse(Segm_table$M %in% outliers, 1,0)
Segm_table$OutliersP = ifelse(Segm_table$P %in% outliers2, 1,0)
#Removing outliers by subseting the data by selecting only cases where this two variables have value "0" (no outlier)
Segm_table_v1=subset(Segm_table,Segm_table$OutliersM==0 & Segm_table$OutliersP==0 )
#Finally, we can remove the "outlier identifiers" variables
Segm_table_v1= Segm_table_v1[,c(-4,-5)]
#Visualization
par(mfrow=c(1,2))
hist(Segm_table_v1$M, xlab="Sales", )
hist(Segm_table_v1$P, xlab="Quantity")

I will now create the segment variables in a new dataset called "cust.segm". For the tresholds, I will select the quantiles of each variable.
#creating segment variable for Sales
cust.segm = Segm_table_v1 %>%
mutate(segm.sales=ifelse(between(M, 0, quantile(Segm_table_v1$M, 0.25)), "1",
ifelse(between(M, quantile(Segm_table_v1$M, 0.25), quantile(Segm_table_v1$M, 0.50)), "2",
ifelse(between(M, quantile(Segm_table_v1$M, 0.50), quantile(Segm_table_v1$M, 0.75)), "3",
ifelse(M>quantile(Segm_table_v1$M, 0.75), '4','4'))))) %>%
#creating segment variable for Quantities
mutate(segm.quantity=ifelse(between(P, 0, quantile(Segm_table_v1$P, 0.25)), '1',
ifelse(between(P, quantile(Segm_table_v1$P, 0.25),quantile(Segm_table_v1$P, 0.50)), '2',
ifelse(between(P, quantile(Segm_table_v1$P, 0.50), quantile(Segm_table_v1$P, 0.75)), '3',
ifelse(P>quantile(Segm_table_v1$P, 0.75), '4','4')))))
#Changing segment variables to factos and set the levels with the correspondent labels
cust.segm$segm.sales=as.factor(cust.segm$segm.sales)
levels(cust.segm$segm.sales)[levels(cust.segm$segm.sales)=="1"] <- "<€261"
levels(cust.segm$segm.sales)[levels(cust.segm$segm.sales)=="2"] <- "[€261 €532["
levels(cust.segm$segm.sales)[levels(cust.segm$segm.sales)=="3"] <- "[€533-€1095]"
levels(cust.segm$segm.sales)[levels(cust.segm$segm.sales)=="4"] <- ">€1905"
cust.segm$segm.quantity=as.factor(cust.segm$segm.quantity)
levels(cust.segm$segm.quantity)[levels(cust.segm$segm.quantity)=="1"] <- "<14"
levels(cust.segm$segm.quantity)[levels(cust.segm$segm.quantity)=="2"] <- "[14-29["
levels(cust.segm$segm.quantity)[levels(cust.segm$segm.quantity)=="3"] <- "[29-60]"
levels(cust.segm$segm.quantity)[levels(cust.segm$segm.quantity)=="4"] <- ">60"
# For visualization I will create this new dataset where i will group per segment variables the number of customers.
visualization <- cust.segm %>%
group_by(segm.sales, segm.quantity) %>%
summarise(customers=n()) %>%
ungroup()
#Plot
require(gplots)
with(visualization, balloonplot(segm.quantity, segm.sales, customers, zlab = "#
Customers"))

We are able to see that 574 customers (the majority) are customers that buy less quantities and spend small amounts of money. Nevertheless, 529 customers are in the best segment, once they buy a lot and spend very high amounts.
Customers in the segment >=1905€ and <14 are customers that spend a lot of money but buy very small amounts of different categories. They can receive cross-sell campaigns to make them buy more (different categories from the ones they actually buy).
As we can see, whit this visualization, we can select targeted campaigns and approaches to communicate with the segments that have more interest to develop or retain.
Editorial Stylebook questions:
The first time I performed this analysis in R, did I struggle with it?
Yes, in two major points 1) Getting the dataset in the right "shape" to perform the analysis and 2) in creating the visualization tool
What other tutorials online cover this topic?
If you search for "RFM segmentation in R" you find some usefull tutorials, which I used to help me performing this analysis.
If you search for "RFM segmentation in R" you find some usefull tutorials, which I used to help me performing this analysis.
What aspects of this analysis do other tutorials miss or explain poorly?
Once every tutorial I found was about doing segmentation on RFM variables, they all missed other approaches (i,e using different segmentation variables), which I cover.
Once every tutorial I found was about doing segmentation on RFM variables, they all missed other approaches (i,e using different segmentation variables), which I cover.
Does my post contribute novel information that others have missed?
I tried to use other approaches on first hand and as mentioned above, on the segmentation variables to use and also on the way of getting the dataset in the correct "shape" (in every tutorial I found, the transactional database was not shaped in the same way I do in this post)
I tried to use other approaches on first hand and as mentioned above, on the segmentation variables to use and also on the way of getting the dataset in the correct "shape" (in every tutorial I found, the transactional database was not shaped in the same way I do in this post)
Does my post use a novel dataset, or are these the same data used in other tutorials?
I didn't find any tutorial on same analysis as mine with the dataset I'm using
I didn't find any tutorial on same analysis as mine with the dataset I'm using